最近在准备面试,翻看以前自己对于排序算法的实现,nima…当时脑子是进水了吗,写出来的代码缺东少西,而且再看竟然还忘了。。真是的! 还是重新实现一下吧。。
插入排序
思想: 从第二个数开始依次插入之前已经排好序的序列中。插入的过程是将这个元素和已经排好序的序列倒序比较,若是小于这个元素(从小到大排序)则后移排好序的元素,若是不小于则插入这个元素。
代码:
1 2 3 4 5 6 7 8 9
| function insert(arr) { for(let i=1;i<arr.length;i++){ let j=i,temp = arr[i] while( arr[--j]>temp){ arr[j+1] = arr[j] } arr[j+1] = temp } }
|
分析: 插入排序使用的是增量(incremental)方法:在排好子数组A[1…j-1]后,将A[j]插入,形成排好序的子数组A[1…j].
最坏情况: 输入数组是逆序排序。 最好O(n),最坏O(n^2),平均O(n^2)。
希尔排序
思想:希尔排序又称为缩小增量排序。希尔排序是插入排序的改进版。是依据设定的间隔序列,将数组分成若干个子序列然后分别执行插入排序。
步骤:
- 选择一个增量序列t1,t2,..ti,tj,…tk, 其中 ti>tj,tk=1。(即最后一个的间隔是1)
- 按增量序列个数k,对序列进行k趟排序。
- 每趟排序,根据相应的增量ti,将待排序分割成若干长度为m的子序列,分别对各子序列进行直接插入排序。仅增量为1时,得到最后排好序的序列。
代码:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
| function shellSort(arr) { var len = arr.length, temp, gap = 1; while (gap < len / 5) { gap = gap * 5 + 1; } for (gap; gap > 0; gap = Math.floor(gap / 5)) { for (var i = gap; i < len; i++) { temp = arr[i]; for (var j = i - gap; j >= 0 && arr[j] > temp; j -= gap) { arr[j + gap] = arr[j]; } arr[j + gap] = temp; } } return arr; }
|
分析: 最好最坏平均时间复杂度O(nlgn)。 不稳定
希尔排序不稳定的例子: 19 2 2 1 。 当步长为2时,第二个2会与19 交换,这样两个2的相对顺序会破坏
冒泡排序
思想:重复交换相邻的两个反序元素。
代码:
1 2 3 4 5 6 7 8 9 10
| function bubbleSort(arr) { for (var i = 0; i < arr.length - 1; i++) { for (var j = 0; j < arr.length - 1 - i; j++) { if (arr[j] > arr[j + 1]) { [arr[j],arr[j+1]] = [arr[j+1],arr[j]] } } } return arr; }
|
分析: 冒泡的时间复杂度情况和插入相同。
改进冒泡排序
思想:设置标志,若是在某趟冒泡中未发生置换,则可以直接返回
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
| function bubbleSort(arr) { for (var i = 0; i < arr.length - 1; i++) { var flag = true; for (var j = 0; j < arr.length - 1 - i; j++) { if (arr[j] > arr[j + 1]) { [arr[j],arr[j+1]] = [arr[j+1],arr[j]] flag = false; } } if (flag) { return arr; } } return arr; }
|
选择排序
思想:第i趟就选择剩下的Arr.length-i个中最小或最大的元素和第i个元素互换。
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
| function selectSort(arr) { for (var i = 0; i < arr.length-1; i++) { var min = i; for (var j = i; j < arr.length; j++) { if (arr[j] < arr[min]) { min = j; } } if(i !== min){ [arr[i],arr[min]] = [arr[min],arr[i]] } } return arr; }
|
分析: 最好最坏与平均都是O(n^2). 因为选择排序每次总是要比较完才能确定下来最小(或最大)的那个元素 ,不稳定。
选择排序不稳定例子: 2 2 2 1。 1与第一个2互换导致2的相对顺序破坏
快排—O(n)空间复杂度
思想:快排是分治法的一种。分治法是将原问题划分成n个规模较小而结构与原问题相似的子问题。递归的解决这些子问题,然后再合并其结果,就得到了原问题的解。
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
| function quickSort(arr) { if (arr.length <= 1) { return arr; } var num = Math.floor(arr.length / 2); var end = arr.length -1; [arr[num],arr[end]] = [arr[end],arr[num]] ; var left = []; var right = []; for (var i = 0; i < end; i++) { if (arr[i] < arr[end]) { left.push(arr[i]) } else { right.push(arr[i]) } } return quickSort(left).concat([arr[end]], quickSort(right)); }
|
分析: 快排最好与平均情况都是O(nlgn),最坏的情况是O(n^2)。最坏情况:如果每一层递归上所作的都是最坏情况的划分。上面实现的快排会使得空间复杂度是O(n). 不稳定。
快排不稳定的例子: 1 2 2 2 3. 若选择第二个2作为划分值的时候,第一个2与第三个2会同时在第二个2的左边或者右边,这样也会破坏相对顺序。
快排—O(1)空间复杂度
思想: 使用partition 方法,每次得到子数组的基准元素所在的index,然后根据此index,进行划分,由于是在原地进行的操作,所以不需要进行拼接。
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
| function quickSort(arr, start, end) { if (start < end) { var q = partition(arr, start, end) quickSort(arr, start, q-1) quickSort(arr, q + 1, end) } return arr } function partition(arr, start, end) { var value = arr[end] var i = start - 1 for (var j = start; j < end; j++) { if (arr[j] <= value) { ++i; [arr[i], arr[j]] = [arr[j], arr[i]] } } [arr[i + 1], arr[end]] = [arr[end], arr[i + 1]] return i + 1 }
|
分析: 上面这种实现是在原地进行排序。空间复杂度是O(1)。
由空间复杂度为O(lgn)的快排得到 时间复杂度为线性的第i个顺序统计量
思想: 在一个由n个元素组成的集合中,第i个顺序统计量是该集合中第i小的元素。 求第i小的元素最小时间复杂度是O(n)。
对于最小值与最大值可以通过n-1次比较得出最后结果。这是最快的方法。但是要同时得到最大与最小值,最快的方法是Math.floor(3/2*n)。 方法是每两对之间进行比较。
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
| function partition(arr, p, r) { var num = arr[r]; var i = p - 1; for (var j = p; j <= r - 1; j++) { if (arr[j] <= num) { ++i; var temp = arr[i]; arr[i] = arr[j]; arr[j] = temp; } } var temp = arr[i + 1]; arr[i + 1] = arr[r]; arr[r] = temp; return i + 1; } function randomizedSelect(arr, p, r, i) { if (p == r) { return arr[p]; } var index = partition(arr, p, r); var k = index - p + 1; if (i == k) { return arr[index]; } else if (i < k) { return randomizedSelect(arr, p, index - 1, i) } else { return randomizedSelect(arr, index + 1, r, i - k) } }
|
分析: 时间复杂度是O(n)
快排的随机化版本
思想:每次作比较的基准元素都是随机产生的。
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
| function randomizedQuickSort(arr) { if (arr.length <= 1) { return arr; } var num = Math.floor(Math.random()*arr.length); var numValue = arr.splice(num,1)[0]; var left = []; var right = []; for (var i = 0; i < arr.length; i++) { if (arr[i] < numValue) { left.push(arr[i]) } else { right.push(arr[i]) } } return randomizedQuickSort(left).concat([numValue], randomizedQuickSort(right)); }
|
分析: 大大减少了最坏情况的发生。
归并排序
思想: 归并排序也是分治法中的一种。归并排序中 会将两个排好序的子数组再进行合并成整个的数组。这个Merge的过程时间复杂度是O(n),可以类比成两摞排好序的牌合并成一摞,所以只需n次。
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
| function mergeSort(arr, start, end) { if (start < end) { var middle = Math.floor((start + end) / 2) mergeSort(arr, start, middle) mergeSort(arr, middle + 1, end) merge(arr, start, middle, end) } return arr } function merge(arr, start, middle, end) { var left = arr.slice(start, middle + 1) left[left.length] = Infinity var right = arr.slice(middle + 1, end + 1) right[right.length] = Infinity var i = 0, j = 0 for (var k = start; k <= end; k++) { if (left[i] < right[j]) { arr[k] = left[i] i++ } else { arr[k] = right[j] j++ } } }
|
分析: 最好最坏平均情况的复杂度都是O(nlgn)。空间复杂度是O(n)。
堆排序
思想:堆数据结构是一种数组对象。可以被视为一颗完全二叉树。树中每个结点与数组中存放该结点值的那个元素对应。树除了最后一层外其余层都是填满的。表示堆的数组A是一个具有两个属性的对象:length[A]是数组中的元素个数,heap-size[A]是存放在A中的堆的元素个数。 即A[0…A.length-1]都可以包含有效值,但A[heap-size[A]-1]之后的元素都不属于相应堆。若树的根是A[0],则对于给定了某个结点的下标i,其父节点是Parent(i) = Math.floor(i/2) ,Left(i) = 2i+1, Right(i) = 2i+2.二叉堆有最大堆和最小堆。对于最大堆,除了根节点之外的每个结点i,都有 A[Parent(i)]>=A[i],最小堆是 A[Parent(i)]<=A[i]。在从小到大的堆排序算法中是使用最大堆,在从大到小的堆排序算法中可以使用最小堆。 最小堆通常在构造优先队列中使用。
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54
| function heapSort(A) { BUIDMAXHEAP(A); for (var i = A.length - 1; i >= 1; i--) { [arr[0], arr[i]] = [arr[i], arr[0]] MAXHEAPIFY(A, 0, i); } return A; } function BUIDMAXHEAP(A) { var parent = Math.floor(A.length / 2 - 1); for (var i = parent; i >= 0; i--) { MAXHEAPIFY(A, i, A.length); } } function MAXHEAPIFY(A, i, heapsize) { var l = 2 * i + 1; var r = 2 * i + 2; var largest =i; if (l <= heapsize-1 && A[l] > A[i]) { largest = l; } if (r <= heapsize-1 && A[r] > A[largest]) { largest = r; } if (largest != i) { [arr[largest], arr[start]] = [arr[start], arr[largest]] MAXHEAPIFY(A, largest,heapsize); } } function MAXHEAPIFY(A, i, heapsize) { var l = 2 * i + 1; var r = 2 * i + 2; var largest =i; while(l<heapSize){ if ( A[l] > A[i]) { largest = l; } if (r < heapsize && A[r] > A[largest]) { largest = r; } if (largest != i) { [arr[largest], arr[start]] = [arr[start], arr[largest]] i = largest l = 2*i + 1 r = 2*i + 2 }else{ break } } }
|
分析:
- MAX-Heapify时间复杂度是O(lgn)
- Build-max-heap 以线性时间运行,可以在无序的输入数组基础上构建出最大堆
- HeapSort 运行时间是O(nlgn),对一个数组进行原地排序。 最好最坏与平均时间复杂度都是O(nlgn),空间复杂度O(1)
- 不稳定
堆排序不稳定的例子: 5 5 5 。 第一个5 会与最后一个5互换,这样就会破坏相对顺序
优先级队列
思想: 优先队列是一种用来维护由一组元素组成的集合S的数据结构,这一组元素中的每一个都有一个关键字key。最大优先级队列的一个应用是在一台分时计算机上进行作业调度。这种队列对要执行的各作业及他们之间的相对优先关系加以记录。当一个作业完成或被中断时,用Extract-max从所有等待的作业中,选择出具有最高优先级的作业。 最小优先级队列可被应用于基于事件驱动的模拟器中,在这种应用中,队列中的各项是要模拟的事件,每一个都有一个发生时间作为其关键字。
代码: 下面是基于上面的最大堆实现的最大优先级队列
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
| function heapMaximum(arr) { BUIDMAXHEAP(arr) return arr[0]; } function heapExtractMax(arr,heapSize){ if(heapSize<1){return ;} var max= arr[0]; arr[0] = arr[arr[heapSize-1]]; --heapsize; MAXHEAPIFY(arr,0,heapSize); } function heapIncreaseKey(arr,i,key){ if(key<arr[i]){return false;} arr[i]=key; var parent = Math.floor(i/2); while(i>0 && arr[parent]<A[i]){ var temp = arr[i]; arr[i] = arr[parent]; arr[parent] = temp; i = parent; } } function maxHeapInsert(arr,key,heapSize){ ++heapSize; arr[heapSize-1] = -1*Number.MIN_VALUE; heapIncreaseKey(arr,heapSize,key); }
|
分析: 和堆排序情况相同
计数排序
思想: 计数排序假设n个输入元素中的每一个都是介于0到k之间的整数,当k=O(n)时,计数排序的运行时间是o(n)。计数排序的基本思想就是对每一个输入元素x,确定出小于x的元素个数,有了这一信息,就可以把x直接放到它在最终输出数组中的位置上。假定输入是数组A[1…n],另外还需要两个数组:存放排序结果的B[1…n]和提供临时存储区的C[0…k]。
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
| function countingSort(arr, k) { var b=[], c = []; for (var i = 0; i <= k; i++) { c[i] = 0; } for (var i = 0; i < arr.length; i++) { c[arr[i]] = c[arr[i]] + 1; } for (var i = 1; i <= k; i++) { c[i] = c[i] + c[i - 1]; } for (var i = arr.length - 1; i >= 0; i--) { b[c[arr[i]]-1] = arr[i]; c[arr[i]] = c[arr[i]] - 1; } return b; }
|
分析: 计数排序假设n个输入元素中的每一个都是介于0到k之间的整数,当k=O(n)时,计数排序的运行时间是o(n)。计数排序一个关键的特点就是稳定性。计数排序经常用作基数排序算法的一个子过程。计数排序的稳定性对于基数排序的正确性来说,是非常关键的。
基数排序
思想:给定n个d位数,第1位是最低位,第d位是最高位。
1 2 3 4
| RadixSort(arr,d){ for i from 1 to d so use a stable sort to sort array A on digit i }
|
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
| function radixSort(arr, maxDigit) { var mod = 10; var dev = 1; var bucket = []; for (var i = 0; i < maxDigit; i++ , dev *= 10, mod *= 10) { for (var j = 0; j < arr.length; j++) { var temp = parseInt((arr[j] % mod) / dev); if (bucket[temp] == null) { bucket[temp] = []; } bucket[temp].push(arr[j]); } var pos = 0; for (var j = 0; j < bucket.length; j++) { if (bucket[j] != null) { while (temp = bucket[j].shift()) { arr[pos++] = temp; } } } } return arr; }
|
分析:基数排序适用于范围比较小,并且>=0。 给定n个d位数,每一个数位可以取k种可能的值,如果所用的稳定排序需要使用o(n+k)的时间,基数排序算法能以o(d*(n+k)的时间进行排序
桶排序
思想:当桶排序的输入符合均匀分布时,可以将区间[0,1)划分成n个相同大小的子区间,或称为桶。然后将n个输入数分布到各个桶中去。然后对各个桶中的数据进行排序,最后按次序将各个桶中的数据列出来
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
| function bucketSort(array, num) { if (array.length <= 1) { return array; } var len = array.length, buckets = [], result = [], min = max = array[0], regex = '/^[1-9]+[0-9]*$/', space, n = 0; num = num || ((num > 1 && regex.test(num)) ? num : 10); for (var i = 1; i < len; i++) { min = min <= array[i] ? min : array[i]; max = max >= array[i] ? max : array[i]; } space = (max - min + 1) / num; for (var j = 0; j < len; j++) { var index = Math.floor((array[j] - min) / space); if (buckets[index]) { var k = buckets[index].length - 1; while (k >= 0 && buckets[index][k] > array[j]) { buckets[index][k + 1] = buckets[index][k]; k--; } buckets[index][k + 1] = array[j]; } else { buckets[index] = []; buckets[index].push(array[j]); } } while (n < num) { result = result.concat(buckets[n]); n++; } return result; }
|
分析: 桶排序最好是在符合均匀输入的时候使用,可以符合线性期望时间运行。
计数排序&基数排序&桶排序
这三种排序算法都利用了桶的概念,但对桶的使用方法上有明显差异:
- 基数排序:根据键值的每位数字来分配桶
- 计数排序:每个桶只存储单一键值
- 桶排序:每个桶存储一定范围的数值
总结
一张来自网上很好看的图。。
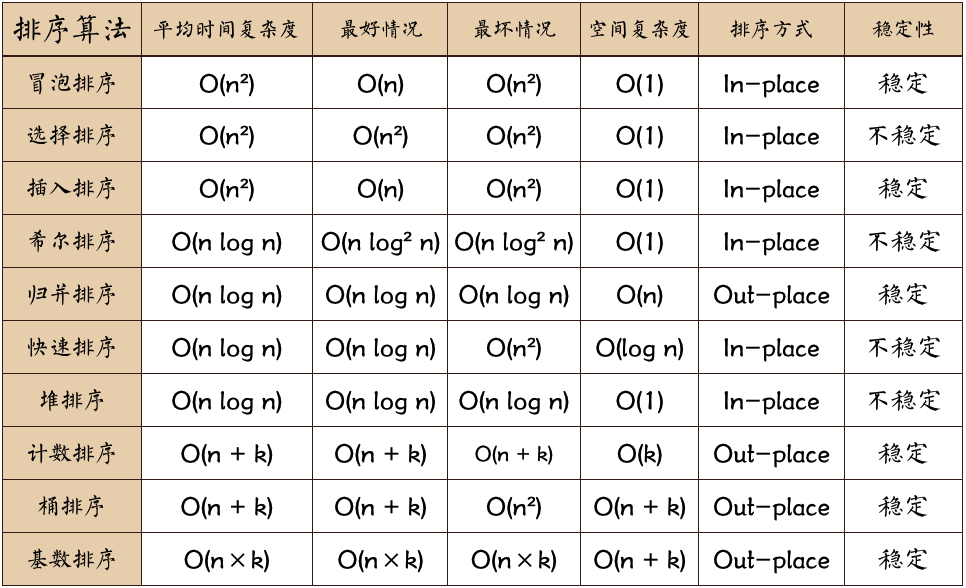
在实际使用的时候是综合的排序,比如javascript中原生的sort 方法。在数据量比较小的时候使用 插入排序,在数据量比较大的时候使用O(n*lgn)的排序算法
一定要经常来复习和完善一下。不然还是不久就忘了。。。
参考文献
- 《算法导论》
- 十大排序算法实现(javascript)
